这是我的第43篇原创

今天跟你聊聊分布式环境的老中医ZooKeeper,专治各种不服。在大数据环境中,这个zookeeper是一个非常独特的存在,很多组件高度依赖ZK,一旦脱离了ZK就无法运行了,比如Kafka、Hbase等。Hadoop生态圈里有很多的动物,什么大象、蜂象、松鼠啥的。ZooKeeper的就像是他的名字一样,是Hadoop体系这个动物园里的管理员,专门负责让这些动物乖乖听话的。
Hadoop生态圈
图是网上找的,好像是个韩国人画的,右下角有版权,但是已经看不清了。
Hadoop是只大象,hive是大象+蜜蜂,Flink是是松鼠,Chukwa是只乌龟,pig是只猪,TEZ是个大象脑袋,TAJO是一只鸵鸟。整个Hadoop体系就像是一个动物园一样,管理着整个动物园。
之前有聊过,所有的分布式场景都会涉及到一致性的问题。于是apache基金会成立了一个项目,把一致性的能力抽象出来,这就有了分布式一致性协调器--ZooKeeper。
ZooKeeper原子广播协议早期的分布式应用都各自实现了一致性的功能。在ZooKeeper出现之后,很多应用直接把一致性的事情交给ZooKeeper了,比如kafka、Hbase等。前面分享过分布式一致性协议的鼻祖-paxos。但是ZooKeeper用的是ZAB(ZooKeeper Atomic Broadcast),也就是Zookeeper原子消息广播协议。
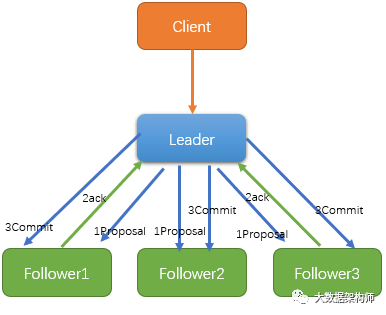
ZAB的逻辑大致如上图所示。与Paxos去中心化不同,ZAB选择了使用一个全局唯一的Leader来做决定。
Leader把客户端的事务请求转化为一个事务Proposal即提案/提议,并将Proposal提案发给集群里所有的Follower节点服务器。
所有Follower收到Proposal提案之后,会给一个ack反馈。
当Leader收到了一半以上的节点的正确反馈后,Leader就会直接下发Commit指令给所有节点。
所有Follower收到Commit指令之后就会递交之前收到的Proposal提案。
这个逻辑是不是很像2PC啊?对,这就是一个简化版的2PC。
但是这个结构有一个致命的问题:Leader是单点的,单点永远最危险。万一Leader挂了怎么办?没事,ZAB有一个崩溃恢复模式,专门应对这种情况,简单来说就是一旦集群里的Leader崩溃了,集群会立刻开始投票,选举一个Leader,然后大家继续进行上面的流程。
ZAB选举流程:
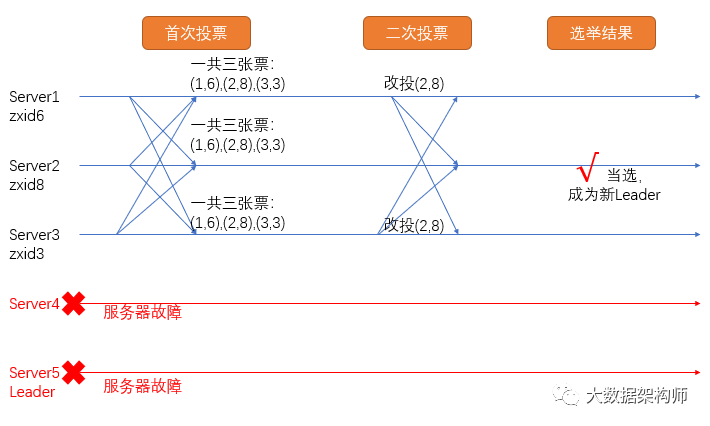
每个服务器都有一个zxid,同时有自己的myid,ZAB就是通过这两个id进行选举的。基本上会通过两个步骤完成选举:
首次投票:每个服务器将自己的MyID和ZXID传给集群中其他所有的节点;
二次投票:每个节点收到所有节点的MyID和ZXID后,先比对ZXID,选取最大的那个,如果ZXID一样,则选取MyID最大的,重新投票。
上面其实已经把ZooKeeper的原理细细的捋了一遍,一句话总结,其实就是二阶段递交+过半写+选举机制。
ZooKeeper一共定义了3种角色:
Leader:全局唯一,负责进行投票的发起和决议,更新系统状态;
Follower:收集客户端的请求,并返回结果,参与投票;
ObServe:提供客户端的读服务,不参与投票,只同步leader的状态。
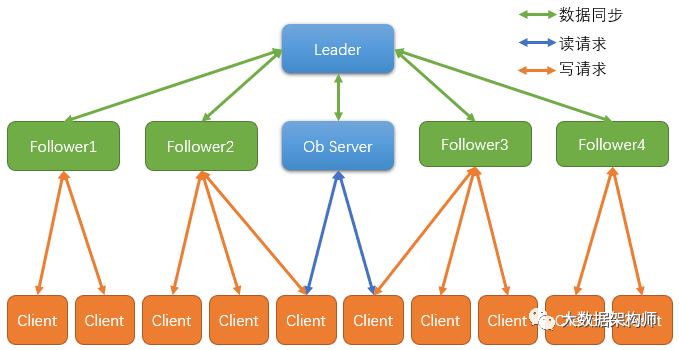
ZooKeeper的每个节点都会存储所有的数据,他们会进行实时的同步。因为ZooKeeper只负责解决一致性的问题,所以其实它们需要存储的数据并不多,因此可以做到每个节点都存储所有数据。
ZooKeeper的Watch机制ZooKeeper在帮助集群达成一致之后,还提供了数据的发布/订阅的功能,这个功能就是通过Watch机制来实现的。
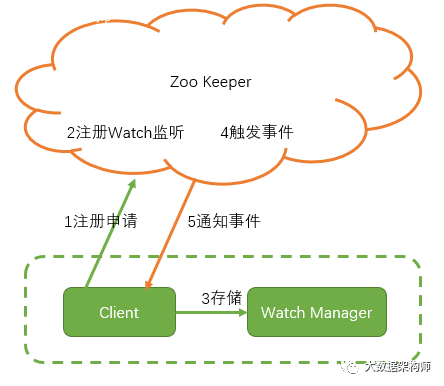
大致的逻辑是这样的:
客户端向ZooKeeper发起注册Watch的请求;
ZooKeeper注册Watch**
客户端把Watch对象存储在WatchManager中
ZooKeeper持续**事件
一旦事件触发,ZooKeeper通知客户端
这样我们就可以得到非常高效的集群内部各种信息发现的服务。这样我们就可以**节点数据变更、节点删除、子节点状态变更等事件,非常的好用。基于这个功能,我们可以把ZooKeeper当做服务发现、数据订阅等用途。
总结ZooKeeper通过ZAB协议,做到集群内数据一致性;
通过选举机制解决Leader单点问题;
通过Watch提供各种**、通知的服务。
另外还有Znode、ACL权限控制等内容去完成数据存储和权限控制的功能。
所以ZooKeeper的功能非常强大,用架构师的话来说,所有分布式系统中的疑难杂症可以直接扔给ZooKeeper,让它给一个结果。
这里罗列一下ZooKeeper的用途:
统一命名服务
分布式锁
数据发布与订阅(配置管理)
负载均衡
分布式通知/协调
集群管理与Master选举
分布式队列
所以也就不奇怪,为啥kafka、Hbase等组件必须强依赖ZooKeeper了,因为它的能力可以完美满足这些组件的各种需求。
往期精彩回顾热文 |快速搞定10亿用户连续7天登录标签干货 |一口气讲完数据仓库建模方法
干货 |数据治理-数据中台的核心内容
 转发,点赞,在看,安排一下?
转发,点赞,在看,安排一下?