这是我的第30篇原创

其实很讨厌有人问窗口函数,因为窗口函数解决的是我在刚开始工作时遇到的问题。因为是BI工程师出身,从业开始就在做各种排名、同比、环比、帕累托占比、当前最大等各种乱七八糟的表格需求。
什么是窗口函数?网上很多数据都写的乱七八糟,搞得好像你越看不懂就显得他越厉害一样。来吧,保证你只要会select,就能看的懂这篇文章!
OK,Let's GO!
什么是窗口函数?一句话解释:
窗口是什么?窗口就是在完整的房子边上开一个大洞,用来通风、观察。
窗口函数是什么?窗口函数就是在完整的表上开一个大洞,在大洞中再开若干小洞,用来观察、计算表中的数据的一类函数。
窗口函数又叫OLAP(onlineAnalytical Processing)函数,其实就是用来画表格的函数。特别擅长处理各种分组排序、同比环比、累计占比、TOP等复杂分析操作。
窗口函数能做什么?
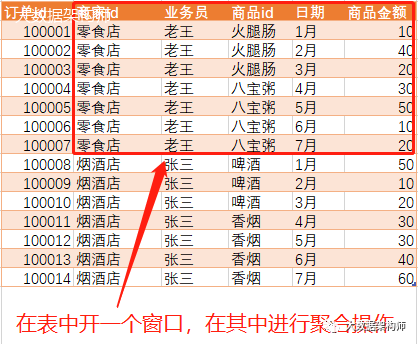
你现在收到一个人事部门的需求:统计每个业务员的每个月的业绩,包括当月业绩、当年最大单月业绩、当年累计业绩。简单设计了一张表,表头如下:

你迅速整理了思路,准备这么做:
1、先把每个业务员每个月的业绩统计出来,存成中间表A表

2、然后根据中间表,统计出当月业绩、当年累计业绩、当年最大单月业绩。
但是你在做的时候发现,当年累计和当年最大单月业绩,每个月的计算范围不一样,截止时间应该是1月到当前月份。所以你想了两种方法:
写一个简单脚本,每次都max和sum,但是执行12遍(月份为参数),当月的数据用join、子查询或者其他方式并进去。
select月份,业务员, max(当月业绩),sum(当月业绩) from a where a.月份<=‘2月’
写一个比较复杂的脚本,用中间表A表join自己,然后join的时候设置月份要小于当前月份,但是得捋很多遍的逻辑,一不小心就会出错。代码我写了一下,头大
 ,如果写错了,私信我,给你发红包~~~
,如果写错了,私信我,给你发红包~~~
select aa.b业务员, aa.b月份, aa.b当月业绩, sum(aa.a当月业绩) as 当年累计业绩, max(aa.a当月业绩) as 当年最大单月业绩 from
(select a.业务员 as a业务员, a.月份 as a月份, a.当月业绩 as a当月业绩,b.业务员 as b业务员, b.月份 as b月份, b.当月业绩 as b当月业绩
from 中间表 A join 中间表 B on a.业务员 = b.业务员) aa
where aa.a月份 <= aa.b月份 group by aa.b业务员, aa.b月份, aa.b当月业绩 order by aa.b业务员, aa.b月份;
你们知道我想说什么。上述的sql都是通过聚合函数(avg、sum、max、min等)+子查询+join来实现的。
实际上大部分数据库除了聚合函数之外,还提供了窗口函数、分析函数、排序函数等各种函数。这些函数结合起来非常好用。
刚才的需求为例,实际上这个需求理解起来非常简单,就是按照每个业务员进行分组,然后在每个分组中,取每个月份的当前值、最大值和累计值。
那么我们只需要一个sql就能搞定三个指标的计算:
select 业务员,月份,商品金额,
sum(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and current row) as 当年累计业绩,
max(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and current row) as 当年最大单月业绩
from 原始业绩表
解释一下:
partition就是对每个业务员的数据单独分组,然后进行内部计算;
orderby就是你计算的时候是按什么顺序进行计算的;
rowsbetween ... and 就是在计算的时候,窗口的区域是从哪里到哪里
unbounded preceding就是当前分组第一行,
current row就是当前行
组合起来就是:
sum(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and current row) as 当年累计业绩,
按照业务员进行分组,月份从小到大排序之后,累计贾总第一个月到当前月的商品金额。翻译成人话就是计算每个业务员当年累计业绩。over。
这就是窗口函数的作用。每个业务员的每份数据都开一个窗口,在这个窗**单独计算。
partition就是以业务员进行开窗(分区),between 和 and就是你在计算这个数值的时候,是否有区域条件(窗**的窗口),and 之前的“unbounded preceding”就是第一条数据开始,and 之后的“current row”就是当前这条数据。
同样,你可以一条语句算出帕累托值(累计占比),不用加辅助字段,不用中间表,不用给自己关联自己,一个窗口函数就搞定。下面两个语句的结果一除就好,语句太长,所以只是计算出来两个字段,没有除出结果。
sum(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and current row) as 当年累计到当月业绩,
sum(商品金额) over (partition by 业务员 order by 月份 asc rows between unbounded preceding and unboundedfollowing) as全年累计业绩,
同样,同比环比也都可以用类似函数直接搞定。怎么样?厉害吧?
窗口函数基本语法:
操作函数(窗口、聚合、排序等)+窗口函数基本内容【 over +partition分区+排序+窗口内区域】
窗口操作函数:
1.LEAD(字段,位移数,默认值) :向下位移N行取值
2.LAG(字段,位移数,默认值):向上位移N行取值
3.FIRST_VALUE:当前分组第一个值
4.LAST_VALUE:当前分组最后一个值
示例:
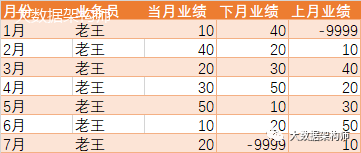
,lead(当月业绩,1,-9999) over (partition by 业务员 order by 月份) as 下月业绩
,lag(当月业绩,1,-9999) over (partition by 业务员 order by 月份) as 上月业绩
窗口函数基本内容:
over (partition by 字段 order by 字段 asc rows between ** and**)
聚合函数
这个就不用解释了吧?聚合就是“多行变一行”的操作。有:
sum、max、min、avg、count
与窗口函数一起用的示例其实上面已经写了几个了,这里就不再复述了
排序函数(分析函数)
1.ROW_NUMBER:从1开始,按照顺序编号
2.RANK:生成排名,相同得分排名相同,并留空位。
3.DENSE_RANK:生成排名,相同得分排名相同,并不留空位。
4.CUME_DIST:小于等于当前值的行数/分组内总行数
5.PERCENT_RANK:分组内当前排名占总排名的百分比
6.NTILE:分桶,将分组内的数据均匀分N桶
示例:
,ROW_NUMBER() over (partition by 业务员 order by 当月业绩) as ROW_NUMBER1
,RANK() over (partition by 业务员 order by 当月业绩) as RANK1
,DENSE_RANK() over (partition by 业务员 order by 当月业绩) as DENSE_RANK1
,CUME_DIST() over (partition by 业务员 order by 当月业绩) as CUME_DIST1
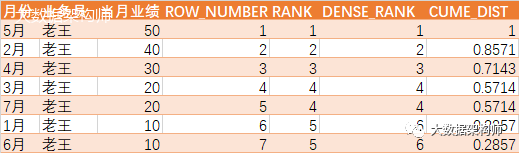
这些在计算绩效的时候非常好用,尤其是业务员的业绩计算,其中有大量排名,业务员之间全国排名、大区排名、省级排名什么的,应用场景非常多。
至于窗口内排名占比和分桶,比较少用,可以存着备用。
写累了...洗洗睡了,希望能帮到你,晚安,好梦~~~
解密|专业HR角度解析完美简历实操 |数据驱动业务全解热文|MapReduce环形缓冲区
 转发,点赞,在看,安排一下?
转发,点赞,在看,安排一下?