西安的美女,多?不多?
反正我觉得很多!

五一期间,陈老师去西安旅游,被城墙、游船、表演、仿古建筑,以及穿梭其中的大量漂亮小姐姐深深吸引了。还有很多小姐姐穿着汉服,打扮得像从画里走出来的一样。于是陈老师在学员群里大呼一声:“西安美女真多呀!”
于是,群里炸了!
排除部分群友强烈呼吁“不要BB,上照片”的言论,大部分人在感慨:“一个做数据的,居然在不认真分析之前,发出如此不靠谱的评论。”然后,在假期闲得无聊的群友们,围绕着:“西安美女到底是不是非常多”进行了激烈的辩论。
1这个数据,该咋分析!关于:“西安美女是不是真的多”,大家的观点可以分作三派:
美女真的多派:这一派认为西安就是美女多,有2种表现
情况1,净人数很多。举例,西安有100万人,广州有90万人。
情况2,比例很高。举例,西安30%的女生都是美女,广州20%。
这一派不但振振有词,而且连理论根据都列出来了,比如:这是以前帝国首都,全世界美女都往这里送所以人的基因好/米脂婆姨绥德汉,吕布貂蝉都在陕。听起来是很有道理的。
美女集中派:这一派认为西安的美女并不特别多,但是集中度高,表现为:
情况3,西安是旅游城市,西安集中的是全国各地的美女
情况4,陈老师去的都是景点,景点集中的是全西安的美女
这一派也很有道理,特别是得知了陈老师住的酒店就在大唐不夜城周围,那边就是景区,平时就有很多小姐姐穿着汉服去拍照,更不用说假期了。
美女不存在派:这一派认为“美”的标准是有问题的,可能:
情况5:因为有地域差异,西安的女生个子高/皮肤白,加上陈老师600度近视,所以一眼扫过去都是美女
情况6:地域差异是不存在的,纯粹是陈老师这个土鳖没见过汉服,所以觉得好看
情况7:汉服的影响也是不存在的,纯纯是陈老师这个老色批,看啥都美……
如果用MECE法梳理逻辑,则如下图所示:
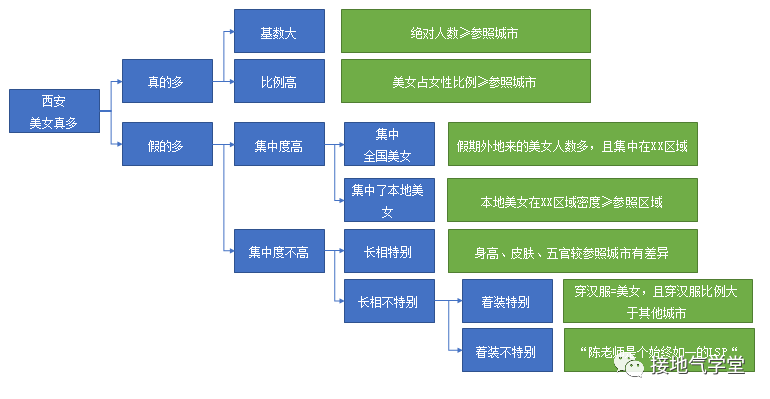
最终,美女不存在派大获全胜,因为陈老师的太太坚决支持情况7,而且老婆的观点就是对的。然而,大家却都很好奇:如果真的用数据验证,到底该咋做呢?
2数据论证,到底咋做?注意,如果认真讨论这个问题的话,情况1和情况2是无解的。因为待论证的问题:“美女”是一个主观评价。主观评价是无法套用到宏观数据上的。
根据7普的统计公报,西安常驻人口1296万;根据西安文旅局公布数据,西安五一期间接待游客数1690万人次,指望人工标注:美女/非美女,根本不可能,因此从源头上,这两个观点无解。
注意!在论证类似问题时,学统计学的同学,很有可能倾向于用一个现成的统计指标,代替“美女”。
比如在陕西省统计年鉴里,可以查到各年龄段性别比。因此有同学会用类似:“18-24岁女性人数”这种指标,用来分析。计算各个城市该年龄段人口比例。这种做法可以得出一个结论,但已经修改了问题判断标准。很有可能遭人质疑:“谁规定的18-24岁就一定是美女!”
情况3、4、5理论上是有解的。因为其考虑的并非全量数据,而是抽样数据。抽样数据的覆盖范围小,因此可以用人工打标注的方法获取数据。但为了避免抽样偏差,需要细心设计抽样方式。为了能对比出结论,最好还有合适的参照组设计。
在调研抽样的时候,考虑越复杂,执行成本就越高。即使只考虑两个因素:
1、景区/非景区
2、假期/非假期
至少得设2个访问点:一个在景区,一个在非景区。同时需要2个观察时间,假期一个,非假期一个。每个访问点的访问员、QC、现场督导,都少不了。如果要计算“美女”在总人群的比例,还得配专门的计数员统计人流。至于场地租金、问卷、计数设备、访问小礼品,都得准备好。
很多同学觉得问问题很尴尬,其实问问题是最简单的一步。比这更奇葩的调查陈老师都做过,比如丐帮的、小偷的、失足妇女的……。只要有小礼品+适当地伪装问题,都能得到配合。
比如调查失足妇女的就能把问卷伪装成避孕套厂商的产品访问……真正难的是设计抽样条件。因为有太多因素能干扰调研结果,考虑太粗,质量不行;考虑太细,费用爆炸。
所以在采用调研手段的时候,企业和政府处理问题的思路完全不一样。企业往往舍量保质,比如一个企业了解西安美女多不多,是想开美容院。那么可以直接在西安地图上圈出几个自己预计进驻的商圈,然后通过调研锁定2、3个商圈里到底哪个目标客户更多。其他影响因素就去他大爷的。
如果是政府(比如统计局)大规模普查,往往保量舍质。就直接用分层随机抽样,抽样条件设计都很简单,比如第六次人口普查,抽样主要考虑的是地区维度,每个城市先选小区,再选住户,保障区域覆盖,没有考虑其他因素(详见《第六次人口普查抽样细则》)。
最好验证的,反而是情况6、7!因为情况6、7跟事实没有关系,只跟陈老师个人有关系。研究一堆人麻烦,研究一个人容易。比如,想验证:陈老师是不是老色批,可以看陈老师是不是:
●去杭州旅游,发:“杭州美女真多啊!”
●去长沙旅游,发:“长沙美女真多啊!”
●去沈阳旅游,发:“沈阳美女真多啊!”
●去西安旅游,发:“西安美女真多啊!”
如果是,嗯!可以确认:陈老师是个发挥稳定的老色批,所以其他情况都不用纠结了!
3数据分析,难在哪里?为啥要花一整篇文章,一本正经地讨论美女,是因为类似的场景,在企业里非常普遍。在实际工作中,人们第一反应就是说评价,而不是说数据。
● 我看XX公司的业绩发展挺好的!
●我看XX产品功能设计挺好的!
●我看XX地区人消费力真高!
而这些主观评价,有可能成为引发内部行动的源头(如下图)
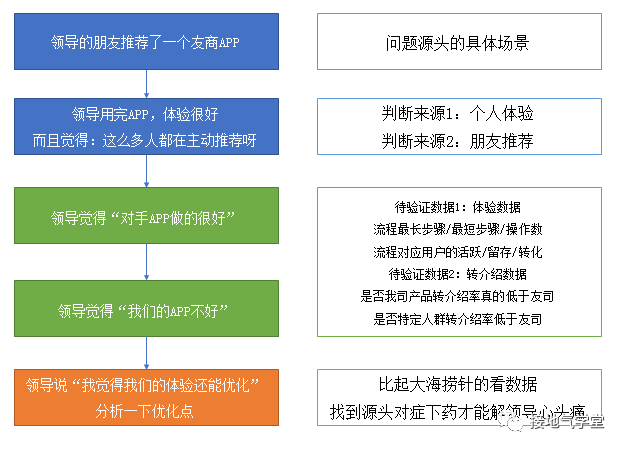
因此当领导甩出一句:“为啥我们在XX地区发展不快?”的时候,专业的数据分析师,第一时间不是去跑数,而是了解清楚问题的源头源自哪里(如下图)
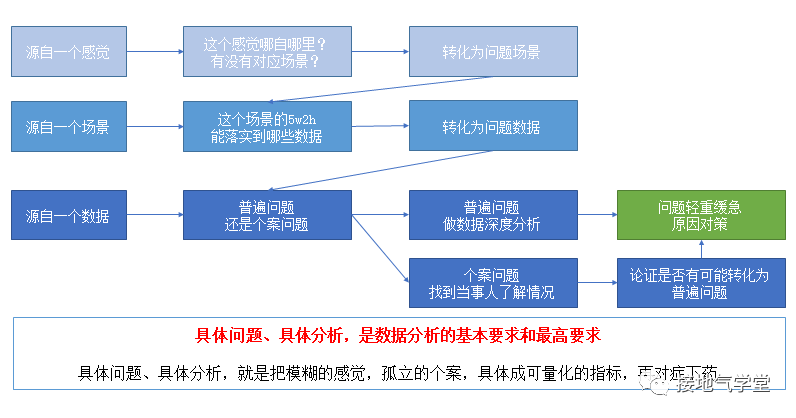
就检验判断的难度而言
●行业性数据≥竞争对手数据
●竞争对手数据≥消费者数据
●消费者数据≥内部数据
●内部数据≥领导个性
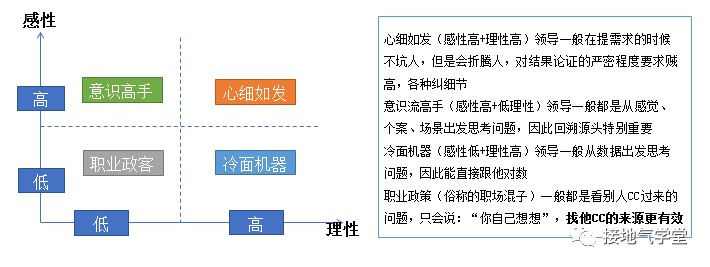
所以在切入问题的时候,要特别关注解决问题的时间成本/经费投入,投入充足才保质保量,投入不足就看舍质保量还是舍量保质,甚至直接从领导习惯入手,直击领导要害都是可以的(如下图)
这些都是基本的工作方法,但很需要再和做数据的同学们强调一下。因为现在网络上关于数据分析的文章太喜欢堆砌“AARRR模型”“拆解法”“对比法”这种抽象概念,完全不讲如何沟通,如何梳理具体场景,误导了很多新人。
具体问题,具体分析是做数据最基本的要求。所谓“具体”,第一顺位要解决的就是各路人马口中的“好/坏”“快/慢”“高/低”这些形容词。遇到形容词:
●评价的源头是啥?
●判断的标准是啥?
●有没有数据支持?
这些要第一时间梳理清楚,不然鸡同鸭讲,南辕北辙,都是常见的。比如90%的数据监控、活动评估、流程优化分析做不好,都是因为判断标准没整明白。有兴趣的话,给陈老师点亮右下角的“在看,”本篇集齐60个在看,我们下一篇分享一个活动评估的例子,敬请期待哦。
-END-
以上就是当我大呼:“西安美女真多呀!”以后……的全部内容了,希望大家喜欢。